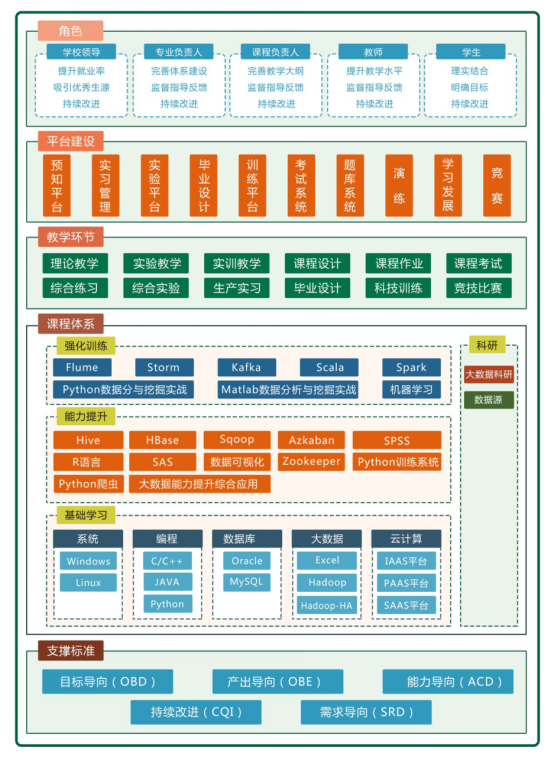
1、系統架構
針對高校大數據專業建設亟待解決的難題,育信科技以工程教育專業認證為標準,圍繞新工科體系建設,為各大高校量身定制了大數據信息一體化的教學科研平臺——智能云教育大數據服務平臺。
以大數據專業建設為核心,成功推出“大數據分析與應用教學實驗系統”,引入最新技術和數據流程理念,轉換大數據項目案例作為課堂實踐實習實訓內容,包括完善的課程體系、教學環節和支撐平臺,提供集專業方向、實戰演練、職業規劃、工程認證、教學體系、課程體系及師資培訓于一體的建設思路,配備完整的大數據軟、硬件環境和配套資源,理實結合,循序漸進全面培養大數據科學與工程領域的復合型技術人才。
從數據的視角,多維度客觀評估教學的主體對象,開展學情管理,實時監控整個教學過程,有效推進完善持續改進,促進高校教學的質量保障!
2、教學體系
教學目標
?人才類型:技能型、應用型、科研型
?多元化教學:理論、實踐教學與大數據分析實戰融為一體,基礎學習、能力提升到強化訓練,逐步提高“學”的質量
?兼顧科研工作:細化知識網絡,引用真實數據源進行大數據科研工作,培養大數據專業復雜工程知識學習和解決能力,充分提升“研”的成效
?全數據采集:為專業認證提供數據支撐、為專業建設提供專項分析、為持續改進提供有效依據
?畢業去向:各行業大數據分析、處理、服務、開發、系統集成與管理維護、研究、咨詢、教育培訓等工作
能力要求
?大數據應用系統設計與開發能力
?一定的科研能力
?知識自我更新和不斷創新能力
?解決復雜大數據工程問題的能力
系統基礎操作——編程語言開發——數據庫操作運維——大數據基礎架構——云環境搭建——數據采集存儲——數據挖掘分析——Python開發設計——機器學習——團隊合作、各司其職——有效溝通、合理解說——方案設計、項目管理——不斷創新、終身學習
3、課程體系
?以輸出結果為導向,通過前置檢索和優選,全面覆蓋實踐教學環節,精選優選案例,完成大數據分析與應用教學實驗系統的建設
?通過基礎學習-能力提升-強化訓練等階段以循序漸進的方式完成大數據專業人才的培養,最終實現大數據教學與其它專業、產業、企業的無縫對接
?微課慕課、圖文并茂學習理論知識,項目訓練、科研訓練、多人組隊進行實踐操作,著力培養學生學習、創新和解決復雜工程問題等綜合能力
?課程體系構建了理論章節98個,涵蓋知識點約600+,微課視頻130+,共202學時教學容量;同時配套實驗420個,練習720個(涉及驗證型516個、推論型146個、設計型58個),教學容量共計341學時
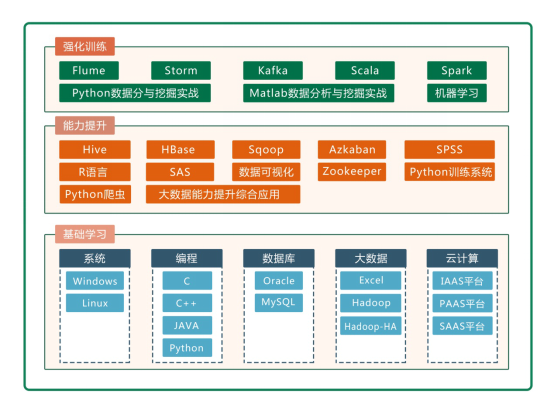
涉及課程資源
階段 | 課程名 | 課程種類 | ||
第 一 階 段 | 基礎 學習 | 系統基礎 | Linux系統管理 | 理論+實驗 |
Windows系統使用 | 理論+實驗 | |||
編程基礎 | C編程語言 | 理論+實驗 | ||
C++語言教學實驗系統 | 理論+實驗 | |||
JAVA編程語言教學實驗系統 | 理論+實驗 | |||
Python編程語言教學實驗系統 | 理論+實驗 | |||
數據庫基礎 | MySQL基礎課程 | 理論+實驗 | ||
Oracle基礎及應用 | 理論+實驗 | |||
大數據基礎 | Excel應用 | 理論+實驗 | ||
Hadoop部署及管理 | 理論+實驗 | |||
Hadoop-HA部署與使用 | 理論+實驗 | |||
云計算 | IaaS_CloudStack平臺搭建及使用 | 理論+實驗 | ||
IaaS_OpenStack安裝部署 | 理論+實驗 | |||
PaaS_Cloudify平臺搭建及使用 | 理論+實驗 | |||
SaaS_SugarCRM平臺搭建及使用 | 理論+實驗 | |||
第 二 階 段 | 能力提升階段 | Hive教程 | 理論+實驗 | |
HBase教程 | 理論+實驗 | |||
Sqoop部署與使用 | 理論+實驗 | |||
Azkaban的部署及管理 | 理論+實驗 | |||
SPSS數據分析與挖掘 | 理論+實驗 | |||
R語言 | 理論+實驗 | |||
SAS數據分析 | 理論+實驗 | |||
zookeeper基礎教程 | 理論+實驗 | |||
數據可視化 | 理論+實驗 | |||
Python訓練系統 | 實驗 | |||
Python網絡爬蟲教學實驗系統 | 理論+實驗 | |||
大數據綜合應用 | 實驗 | |||
第 三 階 段 | 強化訓練階段 | Flume部署及管理 | 理論+實驗 | |
Storm基礎教程 | 理論+實驗 | |||
Kafka基礎教程 | 理論+實驗 | |||
Scala語言 | 理論+實驗 | |||
Spark技術教程 | 理論+實驗 | |||
MATLAB數據分析與挖掘實戰 | 理論+實驗 | |||
Python數據分析與挖掘實戰 | 實驗 | |||
機器學習 | 理論+實驗 | |||
第四階段 | 科研 | 大數據科研 | 實驗 | |
數據源 | 數據源 | |||
4、大數據科研
?針對不同專業,推出“大數據分析與應用科研平臺”,靈活創建切換應用環境
?輕松完成配置平臺與初始化工作,靈活多變提供實訓教學、科技訓練等教學活動
?提供專用硬件設備、多種算法和真實數據源,完成整個大數據科研教學的工程性支撐
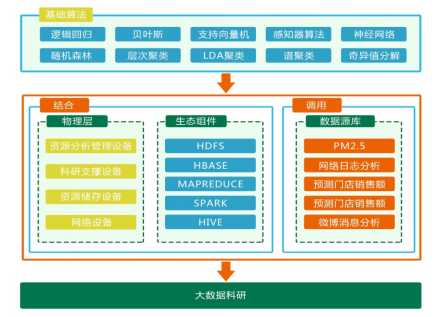
u算法列表
序號 | 算法類 | 算法 |
1 | 分類算法 | 邏輯回歸 |
貝葉斯 | ||
支持向量機 | ||
感知器算法 | ||
神經網絡 | ||
隨機森林 | ||
有限波爾茲曼機 | ||
2 | 聚類算法 | Canopy聚類(重點) |
K均值算法(重點) | ||
模糊K均值(重點) | ||
EM聚類(期望最大化聚類) | ||
均值漂移聚類 | ||
層次聚類(重點) | ||
狄里克雷過程聚類 | ||
LDA聚類(重點) | ||
譜聚類 | ||
3 | 關聯規則挖掘 | 并行FP Growth算法 |
4 | 回歸 | 局部加權線性回歸 |
5 | 降維/維約簡 | 奇異值分解 |
主成分分析 | ||
獨立成分分析 | ||
高斯判別分析 | ||
6 | 進化算法 | 并行化了Watchmaker框架 |
7 | 推薦/協同過濾 | Taste(UserCF, ItemCF, SlopeOne) |
ItemCF | ||
8 | 向量相似度計算 | 計算列間相似度 |
計算向量間距離 | ||
9 | 非Map-Reduce算法 | 隱馬爾科夫模型 |
u數據源
提供包括金融、教育、醫療、商業、交通等21個行業總計400多個數據源
序號 | 行業 | 數據源名稱 |
1 | 金融 | 美國勞工部官方統計數據 |
世界銀行 World Develop,Ment Indicators 數據 | ||
…… | ||
2 | 人力 | 就業和失業(勞動力調查)-歐盟統計局 |
歐盟統計的人工成本年度數據 | ||
…… | ||
3 | 教育 | 美國教育部大學積分卡數據 |
多重性研究的電子探測器數據 | ||
…… | ||
4 | 醫療 | 癌癥CT影像數據 |
軟組織肉瘤CT圖像數據 | ||
…… | ||
5 | 電力 | 美國電力信息_2018年 |
全球電廠數據庫 | ||
…… | ||
6 | 人文 | All-A,Ge-Faces數據集 |
耶魯人臉數據庫 | ||
…… | ||
7 | 電子商務 | 某社交網站上采集到網絡輿情信息和分析對象數據 |
京東產品用戶評論數據 | ||
…… | ||
8 | 物流 | 公路貨物運輸數據-歐盟統計 |
NUTS-2地區高速公路網絡 | ||
…… | ||
9 | 商業 | 用戶對美國航空公司的Twitter評論情緒數據 |
archive-2018-美國消費檔案 | ||
…… | ||
10 | 文體娛樂 |